ODBC Import technique

In this blog post, I will share a technique that Laurent Spielmann (@laurent_at_joes) and I developed together and that greatly simplifies imports. It uses ODBC import.
Have you never been bothered by inconsistent database structures between a data source and your own application?
Have you never cursed the SQL developer who uses as a unicity key a concatenation of several columns?
Have you never felt anxiety before renaming a field because it could break an import order?
Have you never lost your temper in front of a progress bar during a sync operation on a ESS table?
If you answered no to all of these, I’m jealous. This article is for the rest of us. 🙂
Some technical background for a start
FileMaker has had a great friend for a long time: ODBC.
ODBC is implemented in 3 very different manners in FileMaker. Let’s avoid confusion:
- FileMaker can be defined as an ODBC data source. It is not our topic today but it’s interesting because a FileMaker source interrogated via ODBC will act as any other database. An ODBC driver is provided with FileMaker Pro and FileMaker Server.

- FileMaker can access ODBC data in the context of ESS (External SQL Source). The purpose is here to interact with external data as if they were FileMaker data, through table occurrences, layouts, scripts…). Since FileMaker 9, we used to be able to play with mysql, Oracle and SQL Server. Since the release of FileMaker 15, Postgresql and DB2 have joined the game. Note that on Mac, a third party driver is required (Actual Technologies). Since the release of ESS in FileMaker 9, developers tend to use it for all interactions with SQL sources. And that is a very bad idea. I admit that the fact that you can interact with external data just as if they were FileMaker data is great, but the cost in terms of performance is huge. ESS performance is well below ODBC potential.
- Finally, and that is often forgotten -and therefore our today topic— the capability to communicate with a SQL source by script.
What script steps are we talking about?
Two script steps allow interaction with ODBC sources:
- READ: Import records.
- WRITE: Execute SQL (I’m not talking about the ExecuteSQL calculation function, that can only read (SELECT), but of the Execute SQL script step, for good)
Note that it is not possible, at least to my knowledge, to read data from an external source without writing to a FileMaker table (import). One could expect that Execute SQL would return the result of a SELECT statement to a variable, but it doesn’t.
Tip: Execute SQL can also modify the structure of a database. (CREATE, DROP, ALTER…). Come back to this tip after reading this article. Could give you ideas.
Driver ? DSN ? what’s this?
The main reason why these features are somehow neglected is that they require a DSN (Data Source Name) to be installed at the operating system level, and sometimes, depending on the database, a specific driver.
A DSN is needed for the operating system to give applications access to an ODBC data source. ODBC is a standard that allows different databases to communicate using SQL. (Open DataBase Connectivity).
On the Mac, you have to setup a DSN using ODBC Manager, that used to be installed by default in /Applications/Utilities/ before Apple decided it was too good for you. Fortunately, unlike MagSafe connector and other great hardware and software features removed by Apple, ODBC Manager can still be downloaded here.
While it is true that setting up a DSN on each client machine is complex, it’s a snap to install it once on the server.
As a matter of fact, we’ve been able since FileMaker Server 9 to schedule scripts on server, and since FileMaker 13 to perform script on server from the client.
What’s more, and while Import Records [ ODBC data ] has always been server compatible, Execute SQL has become server compatible only with FileMaker Server 15. Enough to re-think some stuff!
To sum up: you can now set up a DSN only on the server and benefit from it on all clients, including Pro, Go, WebDirect and CWP.
However, the developer (that’s you) will also need to access the SQL sources in order to write scripts (namely to configure import orders). To address this you’ll simply have to set up the same DSN on your computer, paying attention to using exactly the same name. So you will be able to edit your scripts and the server can perform them.
We’re done with the technical setup. Now let’s focus on what’s interesting.
The plot
Here is a short summary of the situation we had to address. We have to import a massive amount of data stored in mysql.
Performance is a key here, and this excludes ESS immediately. By the way, we had really no reason to consider ESS: this technology is good at one thing only: present and manipulate external data as if they were FileMaker data. Nothing else. It’s really NOT designed to import or run synchronization operations.
So we go for ODBC imports, but refinements are to come later.
First challenge: unicity and performance
So here we are with the following script configuration:

As you can see, the Import records script steps is talking to a DSN with a query that we define as a variable for the sake of readability.
But among the numerous imports we have to make, some are of ‘update’ type (the third option checked in the import order dialog)
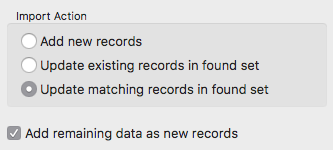
The problem is that the unicity criteria does not fit in a single column. To decide wether a record matches and must be updated, 3 columns had to be used as matching keys.
FileMaker allows this, but with dramatically poor performance. Since the number of records was huge, this simply wasn’t an option.
Imagine the query:
SELECT a, b, c, d FROM myTable
But although we want to import these 4 columns into 4 FileMaker fields: A, B, C, and D, we must update records if a, b and c are matching A, B, and C.
Let’s define the import order like:
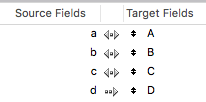
but we know that performance won’t be acceptable.
One way —I’m serious here— would be to ask the SQL developer to update the view and add a column that would concatenate the 3 others. In our situation it would have been a reasonable option, but very often you have simply no control over the source structure.
Let’s see if we couldn’t have mysql do the work for us…
First, let’s create a FileMaker calculation field that will be a unique key on the destination side.
K is a calculated field such as
A & B & C
Now, let’s update the query like:
SELECT CONCAT (a, b, c) AS K, a, b, c, d FROM myTable
Some explanations:
- a 5th column is created on the fly (concatenation of a, b, and c).
- we move before the others (optional, that’s just to show them who’s the boss.)
- it’s renamed K, just because it looks nice (but you’ll see, that will give us ideas. Beauty IS important.)
By selecting the Matching names options, we end up with this:
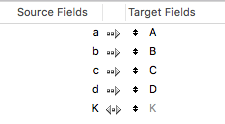
and that is way faster!
Second challenge: naming
Wait! that’s interesting, isn’t it? OK, we solved the performance issue, but while doing so we really took control over the left side of the import order dialog (source).
And one of the great issues we face with import records in FileMaker is it’s fragility. The only way to maintain an import order, even if you create or remove fields is to choose Matching names, but then you’re exposed to the consequences of renaming.
As we just saw, we can control the name of the left side columns. Those who already used XSLT to import XML data already knew, but it’s worth mentioning.
In the above example, I simplified the column names in a, b, c, d and the field names in A, B, C, D, but as you probably expect the real world names were a bit more complex.
Imagine that the original request would be:
SELECT name_first, name_last, jobTitle, date_of_birth FROM PEOPLE
and that the target field names would be
firstName, surName, occupation, dob
we can write:
SELECT name_first AS firstName, name_last AS surName, jobTitle as occupation, date_of_birth as dob FROM PEOPLE
and with the concatenation:
SELECT CONCAT (name_first, name_last, jobTitle) AS K, name_first AS firstName, name_last AS surName, jobTitle as occupation, date_of_birth as dob FROM PEOPLE
Fantastic! we can now use the Matching names option!
Still we knew that the SQL developer might want to rename some columns, or even release new views to replace the old ones after some weeks (this is a real case, not fantasy)
So we wanted to build a system that would resist a change on the source side. Not that the change would be entirely automated, but we wanted to be able to switch to a new source in minutes, without coding. That’s where our work began.
The nice little trick
Wouldn’t it be nice if each FileMaker table was able to generate it’s own import query?
We saw that the left side of the import order could be managed on the fly. It is therefore up to the right side (the database structure) to contain the information.
One spot seemed nice for this: field comments.
Let’s create a small syntax that will:
- declare the left side column name. We’ll use a tag, « SOURCENAME: » followed by the source column name.
- allow to modify this name easily: we’ll simply have to change the column name that follows the tag.
- to comment out. If // is found before SOURCENAME:, the tag is ignored
- not interfere with other information you’d like to place in the comments. As you can see on the image, you can combine a source name and some other comments.

Then we need to create a custom function. (the code is available in this text file)
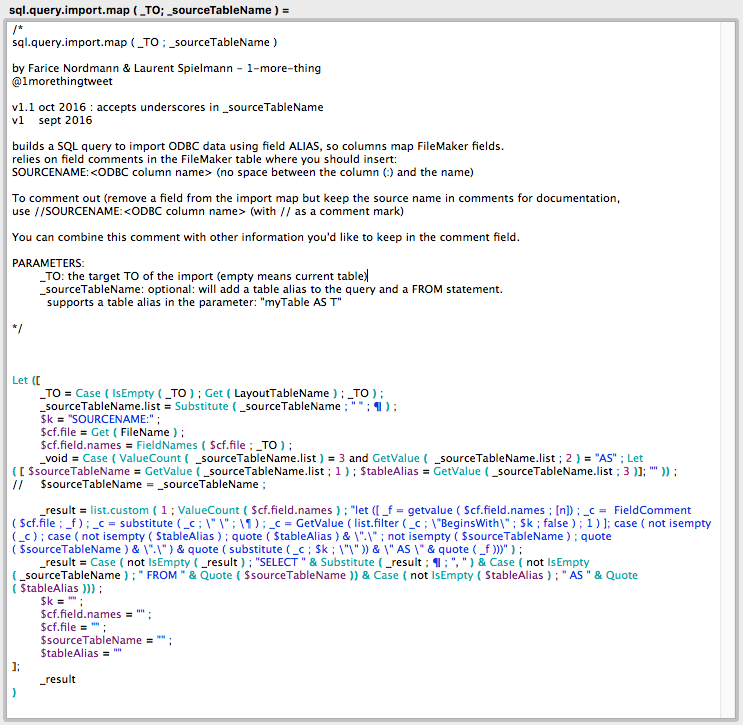
It might look a little complex at first glance but:
- a great part of the work is done by 2 other functions written by Agnès Barouh, CustomList and FilterList, that we renamed list.custom and list.filter. As a side note, Agnès now develops the Ti’Sac, that we sincerely recommend (it’s not simple politeness here, it’s a amazingly clever, unique, patented purse). Christmas is coming, so you should definitely take a look here.

- if it wasn’t a bit complex, you’d be disappointed.
In fact, this function code doesn’t matter. If for the above mentioned table we evaluate the following expression:
sql.query.import.map ( "" ; "contacts AS C" )
the empty parameter indicates « current table ». One can also write:
sql.query.import.map ( "people" ; "contacts AS C" )
the result is:
SELECT "C"."CIE" AS "company", "C"."familyname" AS "name" FROM "contacts" AS "C"
which is exactly the query we need to pass to the script step Import records to have consistent source and destination names.
Here is the same image again:
- Field ‘company’ will receive data from column ‘CIE’
- Field ‘excluded’ won’t receive data
- Field ‘inactive’ won’t either
- Field ‘name’ will receive ‘familyname’
And conflicts with SQL reserved words are avoided using quotes.
The second parameter, « contacts AS C », could have been « contacts », but the function supports table aliases. This will allow importing from joints in the future (currently not supported by the function)
Finally, this second parameter is optional, so you can inject SQL functions in the query:
sql.query.import.map ( "" ; "" )
returns:
SELECT "CIE" AS "company", "familyname" AS name
So if you need to do more complex things you can:
sql.query.import.map ( "" ; "" ) & ", CONCAT ( column1, column2 ) AS myField FROM contacts"
As you can see, this techniques opens up a lot of possibilities. Whether you’re importing from an external source or from the FileMaker database itself.
If you combine this with the fact that an import script step is able to create a new table, that Execute SQL is able to delete this table (DROP), that you can now duplicate a record set without being limited because a table cannot import to itself, etc, etc… the potential is huge!
Do not hesitate to leave a comment here, and now it’s up to you to explore!



Merci beaucoup for translating this into English. A very helpful technique ! 🙂